

Qu’est-ce que la Data science ?
On entend de plus en plus parler de Data Science, c’est le terme à la mode dans les entreprises, sur la toile et dans les écoles. Qu’est-ce donc cette discipline ?
La science des données (Data Science) n’est rien d’autre qu’un domaine multidisciplinaire dont le but est d’utiliser des données (Numériques) pour résoudre des problèmes de la vraie vie ou pour apporter une certaine valeur qu’on appelle « Product Data ».
La science des données (data science) est l’extraction de connaissance d’ensembles de données. Elle emploie des techniques et des théories tirées de plusieurs autres domaines plus larges des mathématiques, la statistique principalement, la théorie de l’information et la technologie de l’information, notamment le traitement de signal, des modèles probabilistes, l’apprentissage automatique, l’apprentissage statistique, la programmation informatique, l’ingénierie de données, la reconnaissance de formes et l’apprentissage, la visualisation, l’analytique prophétique, la modélisation d’incertitude, le stockage de données, la compression de données et le calcul à haute performance.
Wikipédia – Sciences des données
Quelle différence y a-t-il entre Data Science, Big Data et Data Mining ?

La différence entre Data Science et Big Data est immédiate. Le Big Data est la discipline qui consiste à traiter et exploiter une grande quantité de données tandis qu’en Data Science on ne définit pas de contrainte sur la quantité de données. Il vient donc qu’on peut avoir recours aux techniques de Big Data en Data Science quand la quantité de nos données à traiter devient très importante.
La différence entre le Data Mining et la Data Science par contre est un peu moins évidente à tel point que certains confondent les deux. S’il existe une différence entre ces deux termes, elle vient du fait que le Data Mining est une partie de la Data Science. Le Data Mining ne consistant qu’en l’exploitation de données, la Data Science est plus large vu qu’elle prend en compte l’acquisition des données par exemple.
Cette définition peut paraître vague mais cela vient du fait que la discipline est large et fait elle même appelle à plusieurs disciplines.
Domaines intervenant en science des données (Data Science)
Il est important de comprendre que le but final de la science de données est de résoudre un problème dans un domaine précis. Ceci dit, il est indispensable d’avoir une très bonne connaissance du domaine d’application avant de se lancer dans l’élaboration d’un modèle.
Il convient également de noter que les domaines énumérés ci-dessous ne représentent aucunement une liste exhaustive des disciplines intervenant dans la science de donnée. En effet, la fin justifiant les moyens, on peut faire de la data science de diverses manières pour peu qu’on soit dans le contexte présenté plus haut.
En général la sciences des données fait intervenir les disciplines suivantes :
- Le domaine d’application : Il faut entendre par domaine d’application, le secteur (L’environnement) dans lequel on souhaite réaliser un data product ou résoudre un problème. Il peut s’agir par exemple du marché boursier. Si nous voulons établir un modèle prédictif pour les traders basé sur les cours passés des actions.
- Les mathématiques (Statistiques, Probabilités, Algèbre linéaire, Analyse, …) : Les mathématiques interviennent lourdement en data science. En effet, les problèmes sont très souvent traduits en modèles mathématiques avant d’être résolus.
- L’informatique : L’informatique est la base de la science des données dans ce sens où les modèles sont implémentés avec du code et/ou des outils informatiques. Les données étant numériques leur acquisition, leur stockage et tout le traitement est fait grâce à de l’informatique.
- Le machine learning : Les techniques de machine learning sont de plus en plus utilisées en science de données.
- L’algorithmique : La maîtrise de cette science est indispensable vu que toutes les modélisations sont sous forme d’algorithmes. Il est important de de comprendre les concepts tels que la complexité.
- Du bon sens 😉 : Qui est de loin ce dont on a le plus besoin face à un problème complexe.
Bien évidemment être data scientist n’implique pas être expert dans tous ces domaines (même si plus on a de connaissance dans ces domaines, mieux c’est). En effet, un projet de science de données est très souvent complexe et composé de plusieurs étapes. On peut donc trouver dans une équipes des personnes avec différents profils chacun étant en charge d’une étapes précise.
Étapes d’un projet en Data Science
Vive le CRISP-DM (standard utilisé pour un projet de science des données) !
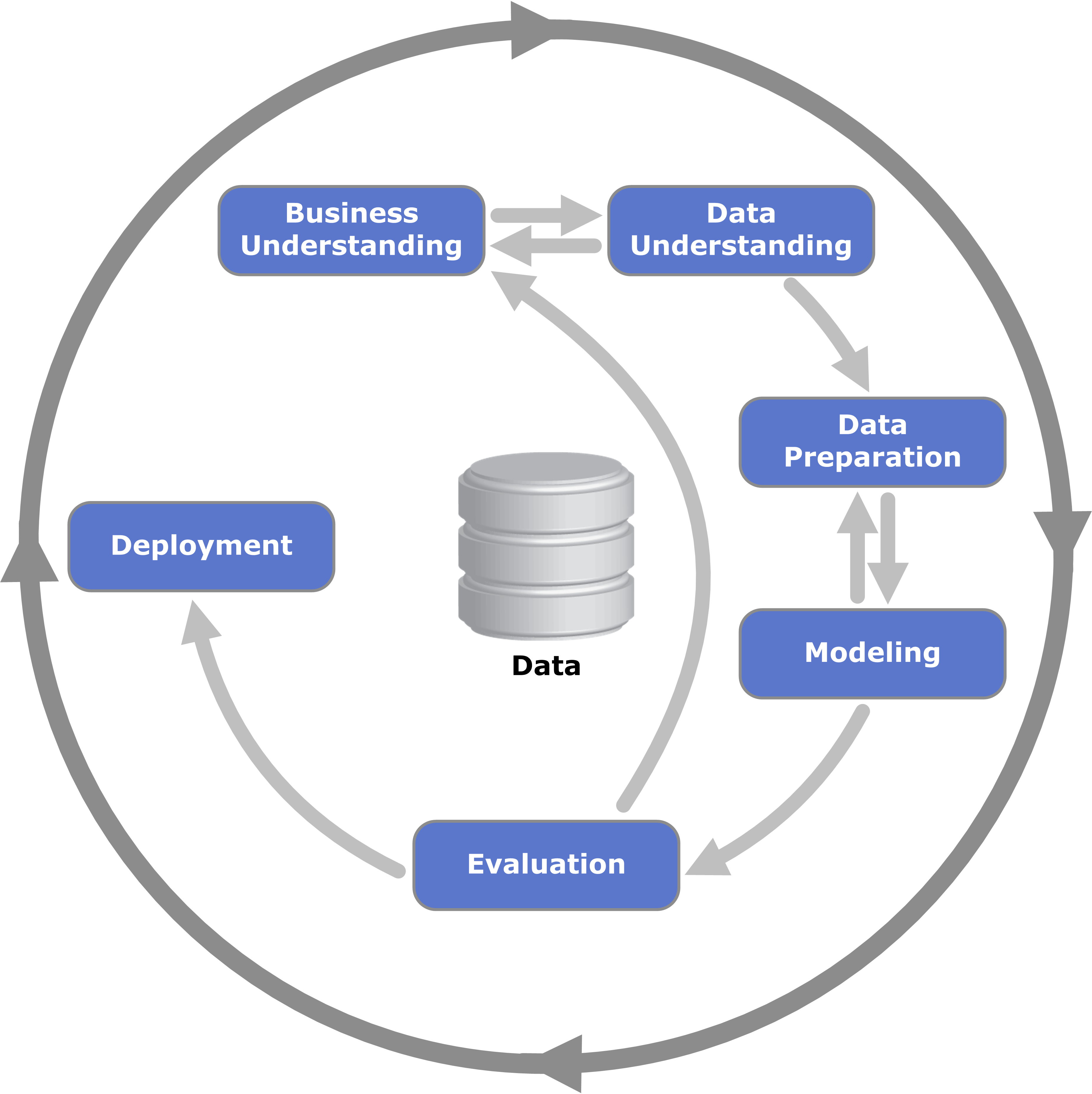
Un projet en science de données peut se voir comme la succession des étapes suivants :
-
- La compréhension du problème métier
Il s’agit reformuler le problème afin de le rendre le plus clair possible. À l’issue de cette étape on doit être capable de savoir plus ou moins quel chemin emprunter dans tout le projet.
-
- L’acquisition des données brutes:
Il s’agit d’aller chercher les données sur lesquelles il va falloir travailler. Ces données sont censées être identifiées à partir de la première étape.
-
- La préparation des données
Les données obtenues à l’étape précédente sont brutes et non structurées. Cette étape a pour but de les nettoyer et les structurer selon nos besoins.
-
- La modélisation
Il s’agit de mettre en place notre modèle, notre algorithme, notre solution pour résoudre le problème d’origine.
-
- L’évaluation
Il s’agit de tester l’efficacité de notre modèle puis passer à l’étape suivante si on a des résultats satisfaisants ou reconsidérer le modèle de l’étape précédente (voire remonter à l’étape 2).
-
- Le déploiement
Il s’agit de la dernière phase, la conclusion qui donne la solution à notre problème.
Il y aura bientôt une série de tutoriels sur chacune de ces étapes.

