

En tant qu’êtres humains nous avons la capacité de transférer les connaissances acquises pour une tâche spécifique dans une autre tâche. Plus cette tâche est facile, plus il est facile d’utiliser ses connaissances. Par exemple : savoir faire du vélo peut être utilisé comme base pour apprendre à rouler une moto.
C’est ce principe qu’utilise l’apprentissage par transfert qui consiste à utiliser un modèle déjà développé sur une tâche comme base d’un modèle d’une nouvelle tâche.
Cette approche est très populaire en deep learning, dans la mesure où des modèles pré-entraînés sont utilisés comme point de départ pour les tâches de vision par ordinateur et de traitement du langage naturel étant donné les vastes ressources de calcul et de temps nécessaires pour développer des modèles sur ces problèmes.
C’est ce que j’ai appliqué dans le projet présenté aujourd’hui en utilisant un modèle Fast R-CNN entrainé sur le dataset COCO (ensemble de données de détection d’objets et de segmentation) comme point de départ pour ma tâche de détection de reçus (tickets de caisse) et de leur zone de total sur une image.
L’objectif à long terme ici est de développer un système robuste d’extraction d’informations pertinentes de reçus.
Contexte
J’ai réalisé ce projet dans le cadre d’un test de recrutement proposé par une entreprise spécialisée en computer vision. Ce test consistait à extraire le total de reçus non annotés (200 images) disponibles ici.
Alors comment j’ai procédé?
La tâche s’annonçant difficile sans données annotées, j’ai effectué des recherches et par chance je suis tombé sur un dataset open source de reçus semblables déjà annotés (zone délimitant les reçus, menu, total, etc..). Bingo! J’ai donc décidé d’entraîner le modèle sur ces données déjà annotées et d’appliquer les résultats sur mes 200 images de base non annotées.
Je suis même allé plus loin en prédisant aussi la zone délimitant un reçu dans une image en plus de la zone de total.
Dans cet article, j’expliquerai en détails les points essentiels de l’implémentation de Faster R-CNN avec Pytorch sur un dataset personnalisé. Le code complet de ce projet est disponible sous la forme d’un Notebook sur mon GitHub
Faster R-CNN
Faster R-CNN est l’une des méthodes de détection d’objets les plus populaires. Elle fait partie de la série R-CNN , développée par Ross Girshick et al en 2014, améliorée avec Fast R-CNN pour enfin obtenir Faster R-CNN. Il faudrait un article entier pour expliquer Faster R-CNN au vu de sa complexité, mais en résumé comment fonctionne-t-il ?
- L’image en entrée est passée dans un réseau neuronal convolutif (CNN) pour obtenir une carte des caractéristiques des objets présents sur l’image. Cette partie de l’architecture de Faster R-CNN est appelée réseau «backbone». Pour notre projet on utilisera un réseau ResNet50 avec FPN (Feature Pyramid Network) comme backbone.
- Cette carte des caractéristiques est ensuite utilisée par un réseau de proposition de région (RPN) pour générer des propositions de régions (cadres de délimitation qui contiennent les objets pertinents de l’image) en utilisant des ancres (boîtes de référence de taille fixe placées uniformément dans l’image originale afin de détecter les objets). Ces régions sont par la suite filtrées par NMS (Non-Maximum Suppression) avec un
tensholdde 0.7. NMS est une méthode qui permet de passer au crible les régions proposées et choisir uniquement celles qui sont intéressantes. [1]
- La carte caractéristique extraite par le CNN en 1 et les cadres de délimitation des objets pertinents sont utilisés pour générer une nouvelle carte caractéristique grâce à la mise en commun (pooling) des régions d’intérêt (RoI) déterminées dans l’étape 2.
- Les régions regroupées passent ensuite par des couches entièrement connectées pour la prédiction des coordonnées des zones des objets et les classes de sortie. Cette partie de l’architecture de Faster R-CNN est appelée réseau d’en-tête.
Pour en savoir plus sur Faster R-CNN ainsi que les principes mathématiques derrière toutes les notions présentées précédemment, n’hésitez pas à consulter cette page qui l’explique dans les moindres détails.
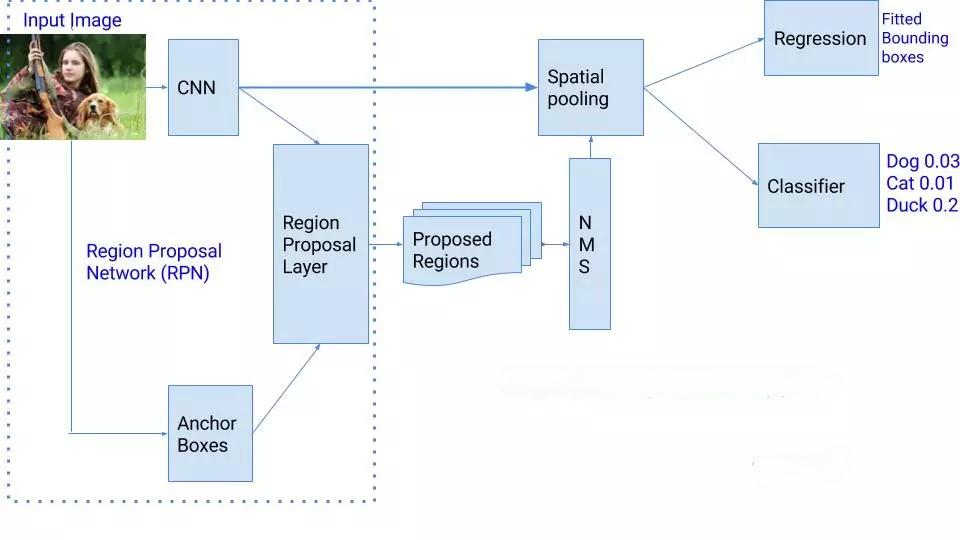
Évaluation d’un modèle Faster R-CNN
L’évaluation est effectuée en utilisant la précision moyenne (mAP) à un certain seuil IoU (Intersection over Union) spécifique (par exemple mAP@0,5).
mAP est utilisée pour déterminer la précision d’un ensemble de détections d’objets à partir d’un modèle par rapport aux vraies annotations d’un ensemble de données.
L’IoU est utilisée lors du calcul de mAP. Il s’agit d’un nombre compris entre 0 et 1 qui spécifie la quantité de chevauchement entre les boîtes des coordonnées prédites d’un objet et les vraies coordonnées dans les annotations.
- Ainsi un IoU de 1 signifie que les boîtes des coordonnées prédites et les vraies coordonnées sont identiques, donc se chevauchent complètement.
- Par contre un IoU de 0 signifie qu’il n’existe aucun chevauchement entre les coordonnées des boîtes prédites et les vraies coordonnées.

Dataset
Nous disposons de 1000 échantillons de données de reçus indonésiens annotés en cinq superclasses (menu, void menu, sous total, void total et total) qui contiennent en tout 42 sous classes telles que la position du reçu, du nom des restaurants, des commandes et du montant total. Ils ont été annotés et mis à disposition de tous spécialement pour les tâches d’analyse post-OCR. A chaque image est associée un fichier json d’annotation contenant les coordonnées de position de chaque zone de texte dans l’image. Vous trouverez le lien du dataset ici et le lien de sa documentation ici.


Les fichiers coco_eval.py, coco_utils.py, engine.py, util.py sont issus du répertoire GitHub officiel de Pytorch pour la segmentation et détection d’image COCO.
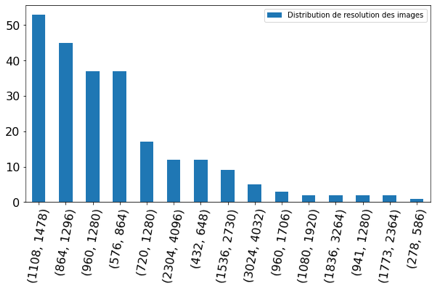
Exploration du dataset avant et après filtrage des coordonnées de reçus
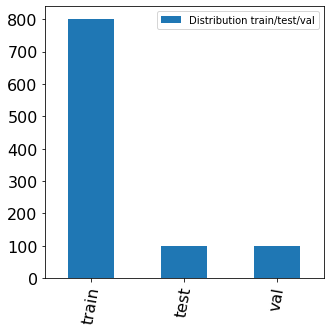
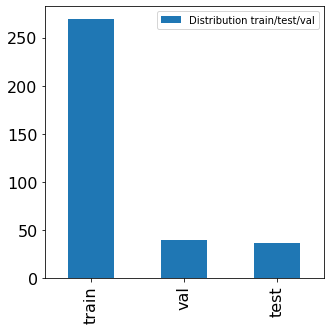
Le dataset d’origine contient 800 images de train, 100 de validation et test. Après sélection des images ayant des coordonnés délimitant les reçus, on se retrouve avec 269 données de train, 50 en validation et 30 en test.
De plus, la distribution de résolution des images ayant des coordonnés délimitant les reçus varie fortement. J’ai donc décidé de redimensionner toutes les images à la taille 817*1230 (moyenne des longueurs et largeurs des 4 premières résolutions apparaissant le plus dans le dataset) afin d’éviter les distorsions le plus possible et permettre la prise en charge de plusieurs images par lots par le GPU.
Implémentation
Nous allons maintenant voir comment implémenter un détecteur d’objets personnalisé en utilisant Faster R-CNN avec pytorch.
Import des bibliothèques requises et visualisation des coordonnées extraites des fichiers JSON :
%matplotlib inline
import os
import pandas as pd
import json
import os
from PIL import Image as Im
import numpy as np
import json
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from matplotlib.collections import PatchCollection
from matplotlib.patches import Patch
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from google.colab import drive
drive.mount('/content/drive/')

Ensuite, nous définissons notre ensemble de données d’entraînement. Pour ce faire, nous héritons de la classe Dataset de PyTorch et créons notre propre classe ReceiptDataset et une classe RoiRescale pour mettre les coordonnées à prédire à l’échelle après redimensionnement des images. Selon la documentation PyTorch, notre classe ReceiptDataset doit implémenter les méthodes __len__ (retourne la taille des du dataset), __getitem__ (permet l’indexation des données) et les méthodes __init__ et __call__ pour la classe RoiRescale.
class ReceiptDataset(Dataset):
""" On hérite ici de la classe dataset pour sa modification """
def __init__(self, dataframe, resize_img=None, resize_roi=None):
self.dataframe=dataframe
#initialisation des images-ids,on utilise le nom des fichiers comme id_unique
self.image_ids=dataframe.img_name.unique()
#initialisation des fonctions de redimentionnement
self.resize_img = resize_img
self.resize_roi = resize_roi
def __len__(self) -> int:
return self.image_ids.shape[0]
def __getitem__(self, index):
#lecture des images (on recupère la ligne associée à chaque index(coordonnées reçu et total)
image_id = self.image_ids[index]
row = self.dataframe[self.dataframe['img_name'] == image_id]
total_box=row.coord_total.values[0]
receipt_box=row.roi.values[0]
image = Im.open(row.img_path.values[0])
if self.resize_roi:
#Si une fonction de redimentionnement est fournie, on transforme l'image dans la nouvelle taille définie
total_box = self.resize_roi(total_box, original_shape=(image.size[1], image.size[0]))
receipt_box = self.resize_roi(receipt_box, original_shape=(image.size[1], image.size[0]))
if self.resize_img:
#Si une fonction de redimentionnement est fournie, on met à l'échelle l'image
image = self.resize_img(image)
#concaténation des coodonnées du reçu et du total
boxes=[receipt_box,total_box]
# création de dictionnaire cible et formats appropriés de données pour tensorflow
target = {}
target['boxes']= torch.as_tensor(boxes,dtype=torch.float32)
#on a ici 2 classes
target['labels'] =torch.as_tensor([1,2],dtype=torch.int64)
target['image_id'] = torch.tensor([index])
target['area'] = torch.tensor([(receipt_box[3] - receipt_box[1]) * (receipt_box[2] - receipt_box[0]), (total_box[3] - total_box[1]) * (total_box[2] - total_box[0])])
target['iscrowd'] = torch.zeros((2,), dtype=torch.int64)
return image, target
class RoiRescale(object):
"""Class de redimensionnement des images """
def __init__(self, new_shape):
assert isinstance(new_shape, tuple)
self.new_shape = new_shape
def __call__(self, sample, original_shape):
w_ratio = new_shape[0] / original_shape[0]
h_ratio = new_shape[1] / original_shape[1]
# xmin, ymin, xmax, ymax
return [sample[0]*h_ratio, sample[2]*w_ratio, sample[1]*h_ratio, sample[3]*w_ratio]
Pour notre classe ReceiptDataset, nous avons en entrée le dataframe contenant les coordonnées, image_id (nom des images), chemins de chaque image ainsi que les fonctions de redimensionnement de l’image. Toutes nos images de formation se trouvent dans le dossier «Train». Dans le constructeur, nous initialisons notre dataframe, nos fonctions de redimensionnement et obtenons tous les image_ids uniques pour un traitement ultérieur. Dans la méthode __getitem__, nous pouvons lire l’image en utilisant l’image_id que nous avons dans le dataframe, et nous pouvons également obtenir les coordonnées de toutes les boîtes englobantes associées à cette image.
Nous initialisons ensuite un dictionnaire appelé target, qui sera transmis au modèle pour l’entraînement. Cette cible contiendra les métadonnées de l’annotation comme les coordonnées réelles de la boîte englobante des reçus et leur total, leurs étiquettes correspondantes, image_id, la zone des boîtes englobantes (area). Le paramètre de zone est utilisé lors de l’évaluation avec la métrique COCO, pour séparer les scores de métrique entre les petites, moyennes et grandes zones. Si nous définissons iscrowd sur True, ces instances seront ignorées lors de l’évaluation.
Chargement des données (avec les data loaders)
La prochaine étape est la définition d’un chargeur de données pour l’apprentissage qui chargera les données d’entraînement, validation et test par lots dans le modèle pour l’entraînement. Pour cela, nous utilisons l’utilitaire DataLoader de PyTorch avec une fonction callback pour changer le format de nos images en batch au format liste de tuple et nos targets au format liste de dictionnaire :
images = [tensor([C,H,W]), tensor([C,H,W]), tensor([C,H,W])]targets = [{'boxes': tensor([2,4]), 'labels': tensor([1,2])}, 'boxes': tensor([2,4]), 'labels': tensor([1,2])},'boxes': tensor([2,4]), 'labels': tensor([1,2])}]
# fonction de callback pour changer le format de nos images en batch(tuple) au format liste et nos targets au format liste de dictionnaire
# images = [tensor([C,H,W]), tensor([C,H,W]), tensor([C,H,W])]
# list of dictionary targets = [{'boxes': tensor([2,4]), 'labels': tensor([1,2])}, 'boxes': tensor([2,4]), 'labels': tensor([1,2])},'boxes': tensor([2,4]), 'labels': tensor([1,2])}]
def collate_fn(batch):
return tuple(zip(*batch))
#Chargement de nos datasets
dataset = ReceiptDataset(df_train, resize_img=resize_img, resize_roi=resize_roi)
dataset_val= ReceiptDataset(df_val,resize_img=resize_img, resize_roi=resize_roi)
dataset_test = ReceiptDataset(df_test,resize_img=resize_img, resize_roi=resize_roi )
# definition des data_loader de train et de validation
train_data_loader = torch.utils.data.DataLoader(dataset, batch_size=8, shuffle=True, num_workers=4, collate_fn=collate_fn)
data_loader_test = torch.utils.data.DataLoader(dataset_test, batch_size=8, shuffle=False, num_workers=4, collate_fn=collate_fn)
data_loader_val = torch.utils.data.DataLoader(dataset_val, batch_size=8, shuffle=False, num_workers=4, collate_fn=collate_fn)
Ensuite étant donné que nous avons le GPU (Tesla K80 de Google Colab avec 11 Go de mémoire autorisant 8 images maximum en batch) nous utilisons cuda comme device :
# Entrainement sur le gpu si le cpu n'est ps disponible
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
Initialisation du modèle
# Chargement de l'architechture model ResNet-50 FPN préformé sur le dataset COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 3 # background , zone délimitant les reçus et leur total
#Obtention du nombre d'entrées pour le classifieur Resnet
in_features = model.roi_heads.box_predictor.cls_score.in_features
# modification de l'en-tête du modèle préformé avec de nouveaux pramètres(in_features,num_classes)
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# Utilisation du GPU pour l'entrainement du modèle
model.to(device)
J’utilise ici Faster RCNN de torchvision avec un backbone resnet50. Je définis pretrained = True, donc la fonction retournera un modèle pré-entraîné sur le dataset COCO. Je définis aussi num_classes = 3, en considérant l’arrière-plan, la zone délimitant le reçu et son total comme classes. En somme je modifie ici juste l’en-tête du modèle en remplaçant le nombre de classes COCO par défaut par mes 3 nouvelles classes pour l’entraînement.
Epochs, optimiseur et planificateur de taux d’apprentissage
# Optimiseur SGD
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# definition de l'optimiseur SGD et du taux d'apprentissage
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
# train for 30 epochs
num_epochs = 30
L’optimiseur que j’utilise ici est SGD (Stochastic Gradient Descent). Le planificateur de taux d’apprentissage aide à ajuster le taux d’apprentissage au cours de la formation pour obtenir plus de précision et accélérer la convergence. StepLR est un ordonnanceur qui décompose le taux d’apprentissage de chaque groupe de paramètres par gamma à toutes les époques step_size. Les hyper paramètres gamma et step_size décideront de la décroissance lr. Enfin, le modèle sera entraîné sur 30 epochs.
Entrainement
#liste pour contennir l'erreur à chaque époque
train_loss_list=[]
for epoch in range(num_epochs):
dict_train_loss={}
# Entrainement d'une epoch , avec affichage chaque 100 itérations(fonction mmodifiée pour récupérer la perte d'entrainement)
train_metrics, loss =train_one_epoch(model, optimizer, train_data_loader, device, epoch, print_freq=34)
#On recupére la valeur d'epoch et de perte pour le tracé à la fin de l'entrainement
dict_train_loss['epoch']=epoch
dict_train_loss['loss']=loss.item()
train_loss_list.append(dict_train_loss)
# Mise à jour du taux d'apprentissage
lr_scheduler.step()
# evalution sur le dataset de validation
evaluate(model, data_loader_val ,device=device)
#torch.save(model.state_dict(), 'fasterrcnn_resnet50_fpn.pth')
torch.save(model,'model')
L’entrainement à chaque époque se fait ici avec la fonction train_one_epoch et la validation se fait avec la méthode evaluate provenant du répertoire github de pytorch.
Par défaut la fonction train_one_epoch renvoie un objet de type metric et ne retourne donc pas de perte de validation. Pour l’obtenir, un ajustement du code est nécessaire (voir mon répertoire github ). Quant à la fonction evaluate elle retourne un objet de type Cocoevaluator résumant la précision moyenne et recall moyen des données de validation .
Perte (loss) d’entrainement et précision moyenne sur les données de validation


On obtient une précision moyenne de 82.4% pour un IoU de 0.5 et 69.1% pour un IoU de 0.75 ce qui est un très bon résultat pour un entraînement sur si peu de données.
Visualisation des prédictions sur nos images de base non annotées (de tailles variables) et un reçu personnel de Brest (voir github pour le code complet).


Même si les prédictions de certaines zones de reçu et de total du modèle ne cadrent pas parfaitement avec les vraies zones, celles-ci restent néanmoins très proches. De plus, le modèle arrive à prédire la zone de reçu et de total indépendamment de la langue (reçu personnel) et de la résolution de ceux-ci qui varie fortement.
On voit bien que le modèle à bien appris de la forme des reçus et de la zone de total.
Conclusion
Nous avons ici mis en place un modèle de deep learning capable de prédire la zone délimitant un reçu et sa zone de total. Le modèle fonctionne relativement bien sur les images de bonnes qualités avec des background différents de la couleur des reçus.
Ces prédictions peuvent permettre non seulement d’extraire les reçus d’une image grâce aux prédictions des coordonnées les délimitant. Mais aussi de les traiter plus facilement en extrayant des informations pertinentes.
Des améliorations sont possibles en récoltant plus de données et en appliquant une augmentation de données par des transformations d’images telles que des rotations et zoom afin de pouvoir mieux traiter les images de mauvaise qualité.
Quelle est la suite ?
Utilisation d’OCR pour extraire les informations de total en zoomant sur le reçu dans un premier temps grâce aux coordonnées de celui-ci afin que l’OCR puisse mieux détecter les caractères.
Vous voulez publier sur ledatascientist.com ? C’est par ici

